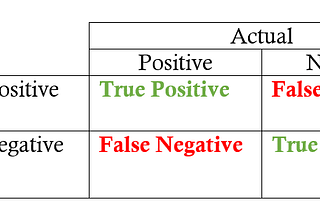
PinnedPrecision-Recall Tradeoff for Real-World Use CasesAce your ML interview by quickly understanding which real-world use cases demand higher precision, and which ones demand a higher recall…Feb 19, 20212Feb 19, 20212
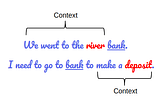
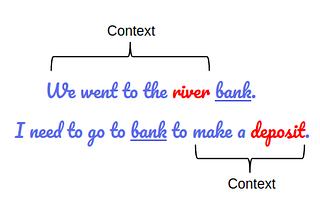
PinnedDifferences Between Word2Vec and BERTWith so many advances taking place in Natural Language Processing (NLP), it can sometimes become overwhelming to clearly understand the…Nov 12, 20203Nov 12, 20203
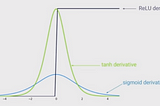
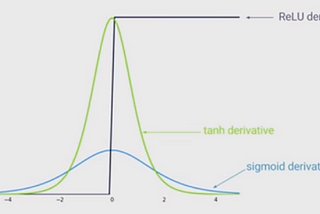
Batch Normalization and ReLU for solving Vanishing GradientsA logical and sequential roadmap to understanding the advanced concepts in training deep neural networks.Apr 26, 20212Apr 26, 20212
Interpreting Logistic Regression Coefficients the Right WayLearn to correctly interpret the coefficients of Logistic Regression and in the process naturally derive its cost function — the Log…Mar 2, 2021Mar 2, 2021
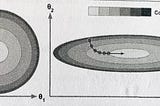
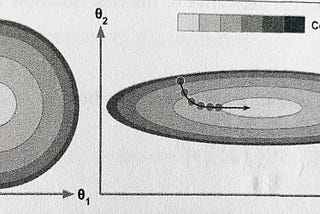
Why Gradient Descent doesn’t converge with unscaled features?Ever felt curious about this well-known axiom? “Always scale your features” Well, read on to get a quick graphical and intuitive…Mar 1, 2021Mar 1, 2021
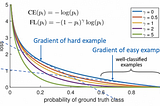
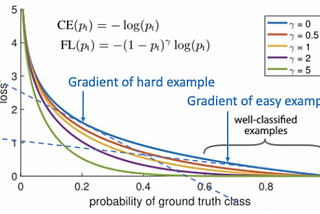
Focal Loss — What, Why, and How?Focal Loss explained in simple words to understand what is it, why is it required and how is it useful — in both an intuitive and…Jan 28, 20212Jan 28, 20212
Published inWiCDSBasics of Image ProcessingEmpower your deep learning models by harnessing some immensely powerful image processing algorithms.Jan 1, 2021Jan 1, 2021
Comparison of Hyperparameter Tuning algorithms: Grid search, Random search, Bayesian optimizationIn the model training phase, a model learns its parameters. But there are also some secret knobs, called hyperparameters, that the model…Nov 21, 20202Nov 21, 20202